At a16z crypto, we’ve talked a lot about how crypto networks are analogous to cities in that both cities and crypto networks benefit from bottom-up growth on top of shared infrastructure.
A traditional business is generally best positioned setting up shop in a location with existing residents, utilities, law, security, and a vibrant market economy. Similarly, developers benefit from building on top of shared resources such as an existing user base, data, security and running code.
We call this composability. A platform is composable if its existing resources can be used as building blocks and programmed into higher order applications. Composability is important because it allows developers to do more with less, which in turn, can lead to more rapid and compounding innovation.
The trustless nature of blockchain computers is a major unlock for composability, as it allows developers to build atop shared infrastructure without fear of lower-level dependencies being yanked from underneath them. This is true because blockchains are both permissionless (what's great about open source) and stateful (what's great about APIs like Twilio and Stripe).
In looking at the evolution of blockchain computing, I’ll sketch out a mental model of four distinct eras, each with varying architectures and priorities with regards to composability:
- Calculator Era - application specific, limited composability
- Mainframe Era - turing complete, high composability
- Server Era - application specific, punt on composability
- Cloud Era - turing-complete, scalable composability
As I describe these, I will walk through the pros and cons of each as I see them. But let me say up front, there are many open ended research questions in this domain, and it is not at all clear how things will shake out. Each is an experiment worth running.
Calculator era
Bitcoin is the forebearer of blockchain computing. It is a full-stack solution to an application-specific problem: sound money or digital gold. Besides the simple function of tracking balances and transfers, bitcoin offers a scripting language that can be used to construct more complex functions.
A number of projects have leveraged Bitcoin Script to compose higher order applications. For example, Proof of Existence leverages the OP_RETURN datastore to create a proof that a specific person had a digital file at a given time. Projects like Colored Coins and Counterparty enable the creation of custom tokens atop the pooled security of Bitcoin’s blockchain. But a number of other attempts to further extend Bitcoin’s functionality, or the functionality of tokens, have been limited by the intentional constraints of the Bitcoin scripting language.
Many argue that that the most important property of a decentralized money system is security, not programmability, and that a limited scripting language is thus a feature, not a bug. Through that lens, we can view Bitcoin as more of a calculator than a computer (and that is intended as a positive remark!). It is purpose built and good at it’s task, but for developers keen to tinker and build new applications an evolution to a new architecture was required.
The mainframe era
Built upon the key ideas pioneered by Bitcoin, Ethereum generalized the blockchain computer by including a turing-complete virtual machine. This means developers can deploy and run any program across a decentralized network of machines.
Today, for veracity, each node in the network must execute every program function. This makes it slow and expensive to use, but Ethereum is unrivaled on one dimension: its computations are trustless. Each program can be expected to obediently execute (as verified) and it’s output, or state, is available for all others to see. A program on Ethereum can thus serve as a dependable and neutral building block for developers to compose into higher order applications. We see this happening today:
Marble enables flash lending for exchange arbitrage: “A trader can borrow from the Marble [smart contract] bank, buy a token on a DEX, sell the token on another DEX for a higher price, repay the bank, and pocket the arbitrage profit all in a single atomic transaction.” To do this, Marble leverages Ethereum’s singleton VM to execute a sequence of functions across independent projects, and the result is a simple utility that anyone can use.
Primotif is a financial derivative that can track real-world indexes, like the S&P 500. It uses Augur shares to track the price of the underlying index, dYdX short tokens to hedge against the volatility of ETH, and dYdX use Maker’s Dai stablecoin under the hood. Built in a weekend, Primotif is a great example of composability leading to compounding innovation and strong developer network effects.
Network effects through composability are not a new phenomenon. Here is Biz Stone, founder of Twitter, on composability of their API in 2007 (via AVC ):
“The API has been arguably the most important, or maybe even inarguably, the most important thing we’ve done with Twitter. It has allowed us, first of all, to keep the service very simple and create a simple API so that developers can build on top of our infrastructure and come up with ideas that are way better than our ideas, and build things like Twitterrific, which is just a beautiful elegant way to use Twitter that we wouldn’t have been able to get to, being a very small team. So, the API which has easily 10 times more traffic than the website, has been really very important to us.”
Unfortunately, composability didn’t last on the Web 2.0 scene. One problem was that there was no way to “send money through the API,” nor an effective and fair means to govern the rules of the platform, such as ad display. This created an incentive misalignment between developers and platforms that resulted in the re-centralization of data and the loss of third-party innovation.
My partner Chris has written about how crypto tokens can better align incentives around sustainable, open networks. The foil, today, is that incentive-aligned, composable networks do not scale.
This is the “mainframe era” of blockchains. While there are no doubt early network effects due to composability—pooled security, userbase, data, and running code—this comes with diminishing marginal returns as adoption pushes against the throughput limitations of the mainframe. This, in turn, drives up cost for each additional user and developer. Plotted on a chart, it looks something like this:
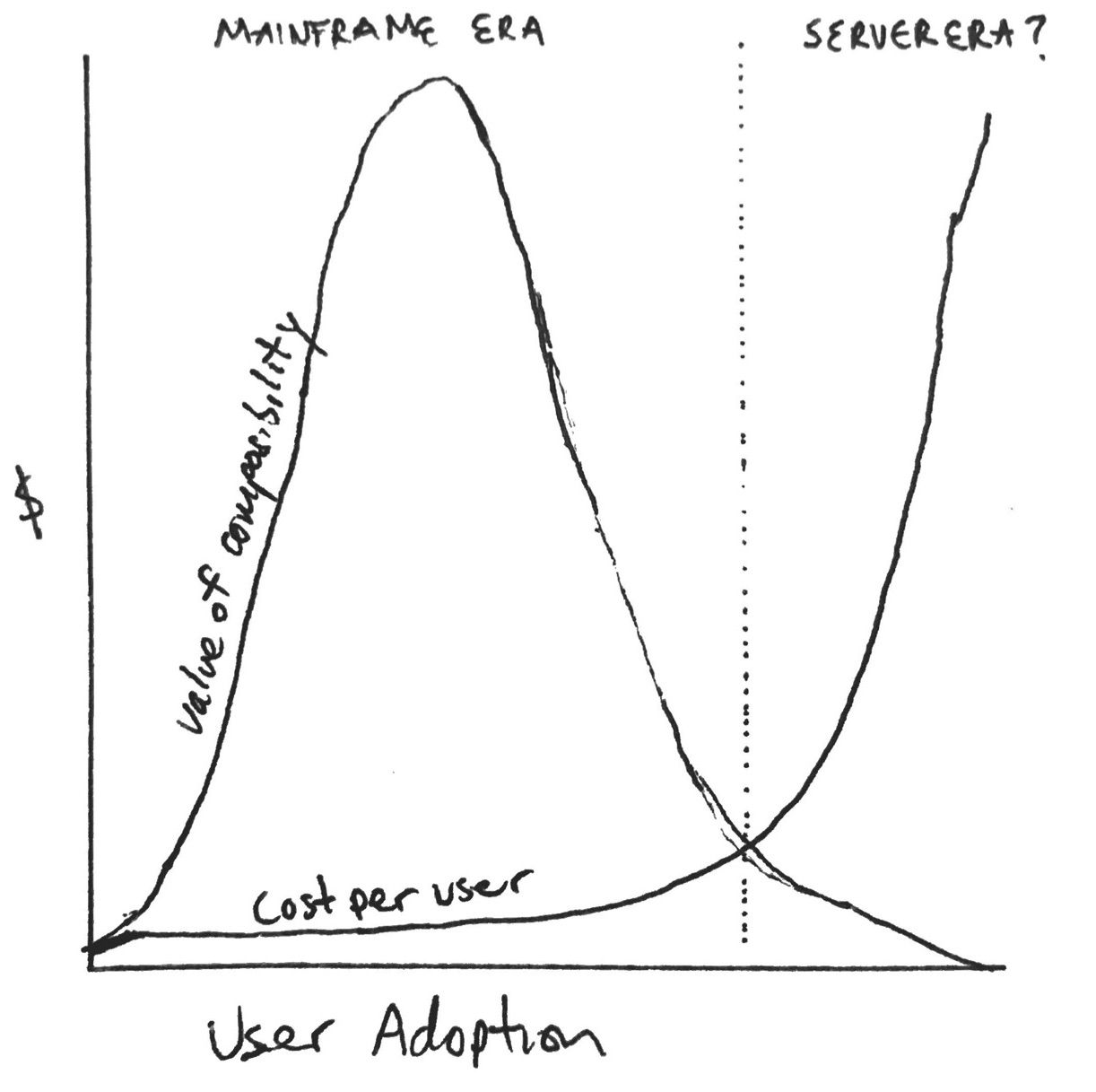
Enter the “server era”
In search of scalability, some developers are foregoing composability and shared network effects, and are instead reverting to application-specific architectures. The vision of projects like Polkadot and Cosmos is one of multiple, heterogeneous chains—each custom tuned for it’s bespoke application. Polkadot’s Substrate and the Cosmos SDK are modular blockchain building kits to roll your own full-stack "app chain."
Going full-stack is a lot more work than composing atop existing network resources. For developers, it means means building down to the state machine and up to the application interface, bootstrapping minimum viable security for the network, and sussing out interoperability with the others in the ecosystem.
But historically, full-stack strategies have proven successful at pulling the future forward and bringing early technologies to market. Wang Technologies offered a very functional word processor as a bundled hardware/software solution long before PC applications were up to par. Later, AOL bundled an ISP, a content delivery system, email and instant messenger—a superior user experience to the early web while it was under construction. And RIM bundled together a mobile device, operating system, and early applications like BBM and push email in order to catalyze smartphone adoption.



In the early days of the web, each website had a custom-built server running in a closet somewhere. In order to own the experience end-to-end, developers needed to own a slice of the infrastructure too. The same may be true for the next era in blockchain computing. This is what I’ve been calling “the server era."
“Server era” blockchains explicitly trade off composability for control. And this plays out on two-dimensions: control over the end-user experience, and more granular control over the economics of the supply-side resources of the network. An assumption of “server era” architectures is that network resources, such-as security, storage, and compute are demand constrained. That is, they can be scaled up, on demand, as the application gains adoption. This stands in contrast to “mainframe era” architectures where resource costs vary as a function of all of the other traffic on the network. The theory is that a full-stack “server era” architectures can mitigate the risk of a gentrifying “mainframe” chain.
“Server era” blockchains are different from their full-stack platform predecessors in that they’re still blockchains! Whereas Wang, AOL and RIM were closed platforms, “server era” blockchains are still verifiable, open data structures with programmable incentives. This property enables them to be composed into hubs (which is what both Cosmos and Polkadot do.) One blockchain can be a light client of another, developers can build atomic swaps, and otherwise extend functionality.
This means that even “server era” blockchains are still composable, but on a different dimension than “mainframe era” blockchains. Rather than running a single virtual machine, these blockchain computers require new standards for communicating with one another in order to enable composition across applications. These communication interfaces are the subject of ongoing research and standardization, and will no doubt add complexity to the developer experience with regards to composibility. But in spite of that drawback, the benefits of a bundle may prove to be the catalyst for a new wave of blockchain architectures and I expect we’ll see many more projects taking a full-stack approach in the near term.
The “cloud era”
The “cloud era” is meant to invoke a scalable, generalized substrate for trustless computation. This is the promised land, where composition is only bounded by creativity, not scale or communication complexity, and where innovation can compound without hitting diminishing returns.
How exactly this will work is very much in the realm of open research. Proponents of “server era” architectures posit that a “cloud era” experience will emerge through standardization and abstraction of inter-blockchain communication among heterogeneous blockchains. Others, like Ethereum 2.0 (Serenity) and Dfinity, are converging on sharded versions of homogenous, turing-complete chains. You can think of this as a world of many “mainframes” that share a pool of security, but split state and computation among homogenous virtual machines. And still others are researching entirely new architectures that move computation off-chain.
Given the size of the research community, and the potential prize for such a solution, I would not be surprised if “cloud era” blockchain computing is hot on the tails of the so-called “server era.” We’ve already laid the cables and built the data centers— “cloud era” blockchain computing is mostly software innovation. Whenever we get there, it seems clear that trustless composability will be a new superpower for developers, and when developers can do more with less, we’ll all be the beneficiaries of more collaboration, creativity, and choice on the internet.